data101
İleri SQL konuları, veritabanı işlemlerini daha karmaşık ve verimli hale getirmek için kullanılan gelişmiş sorgulama ve yönetim tekniklerini içerir. Bu bölümde aşağıdaki konulara değineceğiz:
- JOIN İşlemleri
- Alt Sorgular (Subqueries)
- Gruplama ve Toplulaştırma Fonksiyonları
- Pencere Fonksiyonları
- Görünümler (Views)
- Saklı Yordamlar (Stored Procedures)
- Tetikleyiciler (Triggers)
- İşlemler (Transactions)
- İndeksleme ve Performans Optimizasyonu
4.1 JOIN İşlemleri
JOIN işlemleri, birden fazla tablodan veri çekmek ve bu verileri ilişkilerine göre birleştirmek için kullanılır.
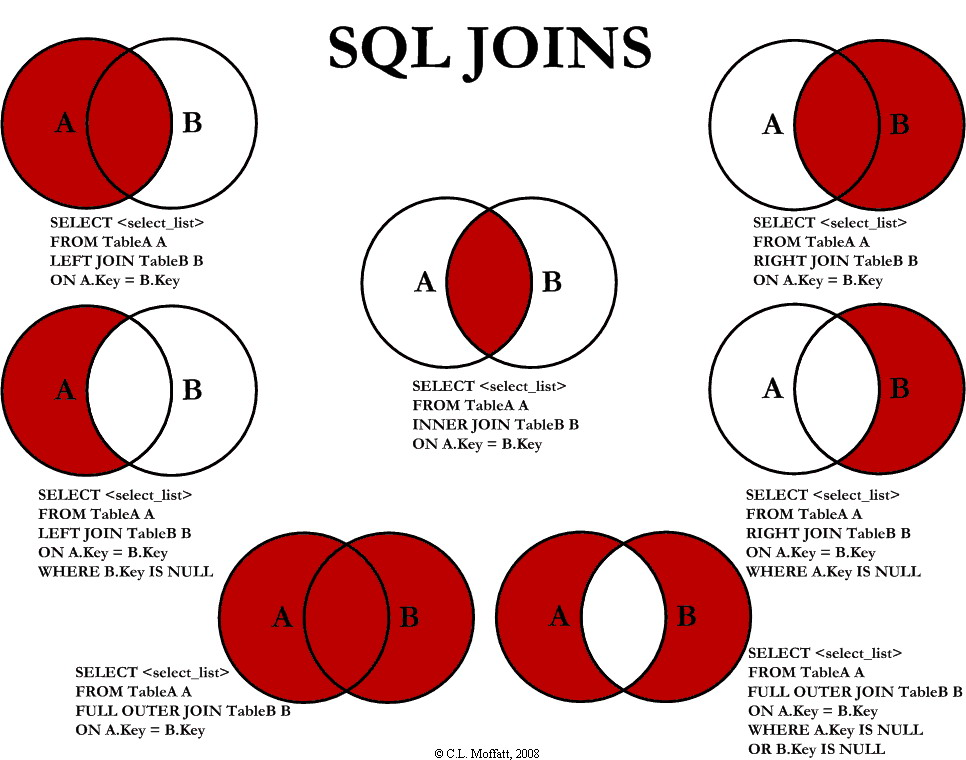
4.1.1 INNER JOIN
Tanım: Her iki tabloda da eşleşen kayıtları getirir.
SELECT
e.first_name, e.last_name, d.department_name
FROM
employees e
INNER JOIN departments d ON e.department_id = d.department_id;
4.1.2 LEFT JOIN
Tanım: Sol tabloda bulunan tüm kayıtları ve sağ tabloda eşleşen kayıtları getirir.
SELECT
e.first_name, e.last_name, e.hire_date
FROM
employees e
LEFT JOIN departments d ON e.department_id = d.department_id;
4.1.3 RIGHT JOIN
Tanım: Sağ tabloda bulunan tüm kayıtları ve sol tabloda eşleşen kayıtları getirir.
SELECT
d.department_name, e.hire_date
FROM
departments d
RIGHT JOIN employees e ON d.department_id = e.department_id;
4.1.4 FULL OUTER JOIN
Tanım: Her iki tablodaki tüm kayıtları getirir; eşleşme yoksa NULL değerler kullanılır.
SELECT
e.first_name, e.last_name, e.hire_date
FROM
employees e
FULL OUTER JOIN departments d ON e.department_id = d.department_id;
4.1.5 CROSS JOIN
Tanım: İki tablo arasında kartezyen çarpım yapar.
SELECT
e.first_name, d.department_name
FROM
employees e
CROSS JOIN departments d;
4.1.6 SELF JOIN
Tanım: Bir tablo içindeki farklı kayıtları birbiriyle karşılaştırmak için kullanılır.
SELECT
e1.first_name AS employee_name, e2.first_name AS colleague_name
FROM
employees e1
JOIN employees e2 ON e1.manager_id = e2.employee_id;
4.2 Alt Sorgular (Subqueries)
Alt sorgular, bir sorgunun içinde başka bir sorgu çalıştırmak için kullanılır.
4.2.1 WHERE İçinde Alt Sorgu
SELECT first_name, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location = 'İstanbul'
);
4.2.2 FROM İçinde Alt Sorgu
SELECT avg_salary
FROM (
SELECT AVG(salary) AS avg_salary
FROM employees
) AS department_avg_salary;
4.2.3 JOIN İçinde Alt Sorgu
SELECT first_name, last_name,
d.title AS department,
concat(e.salary::text, ' TL') AS employee_salary,
CONCAT((ROUND(department_avg_salary.avg_salary) )::text, ' TL')AS department_avg_salary,
CONCAT((round(department_avg_salary.avg_salary) - e.salary )::text, ' TL') AS salary_diff
FROM employees e
INNER JOIN public.department d ON d.id = e.department_id
INNER JOIN (
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
) AS department_avg_salary ON department_avg_salary.department_id = e.department_id
WHERE e.salary < (department_avg_salary.avg_salary * 0.3) order by salary_diff asc;
4.3 Gruplama ve Toplulaştırma Fonksiyonları
Gruplama ve toplulaştırma fonksiyonları, verileri belirli kriterlere göre gruplandırmak ve bu gruplar üzerinde hesaplamalar yapmak için kullanılır.
4.3.1 Toplulaştırma Fonksiyonları
- COUNT(): Kayıt sayısını verir.
- SUM(): Toplam değeri verir.
- AVG(): Ortalama değeri verir.
- MAX(), MIN(): Maksimum ve minimum değerleri verir.
4.3.2 GROUP BY
GROUP BY, sorgu sonuçlarını belirli bir sütuna göre gruplamak için kullanılır.
SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department;4.3.3 HAVING
HAVING, GROUP BY ile birlikte kullanılarak gruplar üzerinde filtreleme yapmak için kullanılır.
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id HAVING AVG(salary) > 75000;4.4 Pencere Fonksiyonları
Pencere fonksiyonları, SQL sorgularında sonuç kümesi üzerinde bir dizi satırı dikkate alarak hesaplamalar yapmanıza olanak tanır. Bu fonksiyonlar, bir sonuç kümesinin bir bölümünde sıralama, gruplama ve diğer hesaplamalar yaparken her satıra özgü değerler döndürürler.
SELECT
first_name, last_name, d.title,
salary,
RANK() OVER (ORDER BY salary DESC) AS salary_rank
FROM
employees
INNER JOIN public.department d ON d.id = employees.department_id;
Bu sorgu, PostgreSQL’de odunc adlı tablodan her üyenin (uye_id) ödünç alma işlemlerini topluca analiz eden bir sorgudur. SUM(adet) OVER (PARTITION BY uye_id ORDER BY odunc_tarihi) ifadesi, her üyenin ödünç aldığı kitapların sayısını kümülatif olarak hesaplar.
4.5 Görünümler (Views)
View, bir SQL sorgusunun sonuçlarını temsil eden sanal bir tablo gibidir. Fiziksel olarak veriler içermez, ancak sorgu çalıştırıldığında, arka planda tanımlı olan SQL sorgusu yürütülerek sonuçlar döndürülür. Yeni kayıtlar eklenirken, güncelleme yapılırken veya silme işlemi gerçekleştirilirken, view’lar otomatik olarak güncellenir ve sonuçlar gerçek zamanlı olarak yansıtılır.
4.5.1 Görünüm Oluşturma
CREATE VIEW employee_not_assigned_department AS
SELECT e.first_name, e.last_name, e.hire_date, e.department_id, e.last_updated_at, (current_date - e.last_updated_at) as not_assigned_days, e.notes
FROM employees e
WHERE e.department_id IS NULL;
4.5.2 Görünüm Kullanma
select * from employee_not_assigned_department where extract(day from not_assigned_days) > 30;
4.5.3 Görünüm Güncelleme
CREATE OR REPLACE VIEW employee_not_assigned_department AS
SELECT e.first_name, e.last_name, e.hire_date, e.department_id, e.last_updated_at, (current_date - e.last_updated_at) as not_assigned_days, e.notes
FROM employees e
WHERE e.department_id IS NULL;
4.5.4 Görünüm Silme
DROP VIEW employee_not_assigned_department;
4.6 Saklı Yordamlar (Stored Procedures)
Saklı yordamlar, veritabanı üzerinde tekrarlayan görevleri otomatikleştirmek ve bir dizi SQL işlemini bir arada çalıştırmak için kullanılan fonksiyonlardır. PostgreSQL’de hem Stored Procedures (saklı yordamlar) hem de Stored Functions (saklı fonksiyonlar) bulunmaktadır, ancak aralarındaki temel fark şudur:
- Stored Procedures: Geriye bir değer döndürme zorunluluğu yoktur ve SQL işlemleri içinde daha esnek yapılar kullanabilirler (örneğin, transaction yönetimi).
- Stored Functions: Geriye bir değer döndürmek zorundadır ve daha çok matematiksel işlemler, dönüş değerli sorgular için kullanılır.
PostgreSQL 11 sürümünden itibaren Stored Procedures desteği eklenmiştir. Bu sayede, özellikle büyük projelerde ya da karmaşık iş süreçlerini veritabanı düzeyinde yönetmek için güçlü bir yapı sunmaktadır.
4.6.1 Saklı Yordam Oluşturma
Stored Procedure Oluşturma PostgreSQL’de bir Stored Procedure şu şekilde oluşturulur:
CREATE PROCEDURE update_employee_salary(emp_id INT, increase_amount INT)
LANGUAGE plpgsql
AS $$
BEGIN
UPDATE employees
SET salary = salary + increase_amount
WHERE employee_id = emp_id;
END;
$$;
Stored Procedure Kullanımı Saklı yordamlar CALL komutu ile çağrılır:
CALL update_employee_salary(50001, 1000);
4.6.2 Saklı Yordam Silme
DROP PROCEDURE update_employee_salary;
4.6.3 Saklı Yordam’da Saklı Yordam Çağırma
CREATE OR REPLACE PROCEDURE create_new_department(department_name VARCHAR(200), employeeID INT, location VARCHAR)
LANGUAGE plpgsql
AS
$$
BEGIN
-- Attempt to insert into department table
INSERT INTO department (title, location) VALUES (department_name, location);
-- Update employee's department
UPDATE employees
SET department_id = (SELECT id FROM department WHERE title = department_name)
WHERE employees.employee_id = employeeID;
-- Update manager_id to NULL for all employees managed by the given employee
UPDATE employees
SET manager_id = NULL
WHERE employees.manager_id = employeeID;
-- Call to another procedure for updating employee salary
CALL update_employee_salary(employeeID, 10000);
EXCEPTION
WHEN OTHERS THEN
RAISE NOTICE 'Error: %', SQLERRM;
END;
$$
Stored Procedure Güncelleme
CREATE OR REPLACE PROCEDURE update_employee_salary(emp_id INT, increase_amount INT)
LANGUAGE plpgsql
AS $$
BEGIN
UPDATE employees
SET salary = salary + (increase_amount * 0.72),
bonus = bonus + (increase_amount * 0.28)
WHERE employee_id = emp_id;
END;
$$;
Stored Function Oluşturma
CREATE OR REPLACE FUNCTION get_employee_salary(emp_id INT)
RETURNS INT
LANGUAGE plpgsql
AS $$
BEGIN
RETURN (SELECT salary FROM employees WHERE employee_id = emp_id);
END;
$$;
Stored Function Kullanımı
SELECT get_employee_salary(50001);
Stored Function Silme
DROP FUNCTION get_employee_salary;
Stored Procedure ve Function Arasındaki Farklar
| Stored Procedure | Stored Function |
|---|---|
| Geriye değer döndürmez | Geriye değer döndürür |
| Transaction yönetimi yapılabilir | Transaction yönetimi yapılamaz |
| Daha esnek ve geniş kapsamlıdır | Daha spesifik ve sınırlıdır |
| Genellikle iş süreçlerini yönetmek için kullanılır | Dönüş değeri hesaplamak için uygundur |
Örnek: CALL update_employee_salary(50001, 1000); |
Örnek: SELECT get_employee_salary(50001); |
Stored Procedure Avantajları:
- Performans: Sorgular derlenir ve saklanır, bu da tekrarlayan görevler için daha hızlı performans sağlar.
- Yeniden Kullanılabilirlik: Aynı işlemleri tekrar tekrar yazmadan kullanabilirsiniz.
- Güvenlik: Veritabanına erişim seviyesini sınırlayabilir ve kullanıcılara doğrudan tablo erişimi yerine sadece saklı yordamlar üzerinden işlem yapmalarına izin verebilirsiniz.
- Transaction Yönetimi: Birden çok SQL ifadesini tek bir işlemde birleştirerek veritabanı bütünlüğünü korumak daha kolaydır.
Stored Function Avantajları:
- Dönüş Değeri: Geriye bir değer döndürdüğü için, hesaplamaları ve işlemleri daha kolay yönetebilirsiniz.
- Modülerlik: Dönüş değeri olan işlemleri diğer sorgularla birleştirerek daha karmaşık işlemler yapabilirsiniz.
- Performans: Stored Functions, sorguları daha hızlı çalıştırabilir ve daha optimize edilmiş sonuçlar döndürebilir.
- Güvenlik: Veritabanına erişim seviyesini sınırlayabilir ve kullanıcılara doğrudan tablo erişimi yerine sadece saklı yordamlar üzerinden işlem yapmalarına izin verebilirsiniz.
- Transaction Yönetimi: Stored Functions, işlemleri gruplandırarak veritabanı bütünlüğünü korumak daha kolaydır.
Her Veritabanında Stored Procedures Var mı ? PostgreSQL’deki Stored Procedures (Saklı Yordamlar), diğer veritabanı sistemlerindeki Stored Procedures ile genelde aynı amacı taşır: bir dizi SQL komutunu bir araya getirip, tekrar kullanılabilir hale getirmek. Ancak her veritabanı sistemi farklı bir dil desteğine ve yapısal kurallara sahip olabilir. Farklı sistemlerdeki saklı yordamlar bazı noktalarda birbirine benzese de, yazım kuralları, kullanılan diller ve işlem yönetimi gibi konularda farklılıklar gösterebilir.
4.7 Tetikleyiciler (Triggers)
Tetikleyiciler, belirli veritabanı olayları gerçekleştiğinde otomatik olarak çalışan prosedürlerdir.
4.7.1 Tetikleyici Oluşturma
CREATE OR REPLACE FUNCTION insert_salary_data_to_history()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO salary_history (employee_id, old_salary, new_salary, created_at)
VALUES (OLD.employee_id, OLD.salary, NEW.salary, current_date);
RETURN NEW;
END;
$$ LANGUAGE plpgsql
CREATE TRIGGER salary_history_trigger
BEFORE UPDATE ON employees
FOR EACH ROW
WHEN (OLD.salary IS DISTINCT FROM NEW.salary) -- Sadece maaş değiştiğinde tetiklenir
EXECUTE FUNCTION insert_salary_data_to_history();
4.7.2 Tetikleyicinin İşleyişi
- Olay: odunc tablosuna yeni bir kayıt eklendiğinde.
- Eylem: İlgili kitabın stok değeri 1 azaltılır.
CREATE OR REPLACE FUNCTION decrease_book_stock()
RETURNS TRIGGER AS $$
BEGIN
UPDATE kitaplar
SET stok = stok - 1
WHERE kitap_id = NEW.kitap_id;
RETURN NEW;
END;
CREATE TRIGGER decrease_book_stock_trigger
AFTER INSERT ON odunc
FOR EACH ROW
WHEN (NEW.kitap_id IS NOT NULL)
EXECUTE FUNCTION decrease_book_stock();
4.8 İşlemler (Transactions)
İşlemler, bir dizi veritabanı işleminin tek bir birim olarak ele alınmasını sağlar.
4.8.1 İşlem Başlatma ve Bitirme
-- employee 6 budget should be increased by 1000
UPDATE employees SET budget = budget + 5000 WHERE employee_id = 6;
-- employee 5 budget should be decreased by 1000
UPDATE employees SET budget = budget - 5000 WHERE employee_id = 5;
eğer employee 6 işlemi başarılı olurken employee 5 işlemi başarısız olursa, ödeme işlemi yapılmış ama para çekme işlemi yapılmamış olacaktır. Bu durumda işlemleri birleştirerek işlemi başlatıp bitirmek daha mantıklı olacaktır.
BEGIN;
UPDATE employees SET budget = budget + 5000 WHERE employee_id = 6;
UPDATE employees SET budget = budget - 5000 WHERE employee_id = 5;
COMMIT;
ROLLBACK;
- COMMIT: İşlemleri kalıcı hale getirir.
- ROLLBACK: İşlemleri geri alır.
4.9 İndeksleme ve Performans Optimizasyonu
İndeksler, veritabanı sorgularının performansını artırmak için kullanılır.
4.9.1 İndeks Oluşturma
* Basit İndeks Oluşturma* Basit indeks genellikle tek bir sütuna uygulanır ve sorguların bu sütuna hızlı erişimini sağlar.
CREATE INDEX idx_kitap_baslik ON kitaplar(baslik);
* Unique Index Oluşturma* Unique indeks, bir sütunda/veya çoklu sütunlarda benzersiz değerlerin saklanmasını sağlar.
CREATE UNIQUE INDEX idx_salary_history_employee_id_created_at
ON salary_history (employee_id, created_at);
* Partial Index Oluşturma* Partial indeks, belirli bir koşulu sağlayan verileri indekslemek için kullanılır.
SELECT
extract(day from hire_date) as day,
avg(salary) as avg_salary,
max(salary) as max_salary,
min(salary) as min_salary
FROM employees
GROUP BY day
ORDER BY day;
şimdi ise partial index oluşturalım. (hire_date alanı null olmayan kayıtları indeksleyeceğiz ve buradaki day alanını indeksleyeceğiz.)
CREATE INDEX idx_employee_hire_date_as_day
ON employees (extract(day from hire_date))
WHERE hire_date IS NOT NULL;
* Multicolumn Index Oluşturma* Multicolumn indeks, birden fazla sütunu indekslemek için kullanılır.
CREATE INDEX idx_employee_first_name_last_name
ON employees (first_name, last_name);
* Functional Index Oluşturma* Functional indeks, sütun üzerinde bir işlem yaparak indeks oluşturmak için kullanılır.
CREATE INDEX idx_employee_full_name
ON employees (CONCAT(first_name, ' ', last_name));
4.9.2 İndekslerin Avantajları
- Sorgu hızını artırır.
- Veri erişimini optimize eder.
4.9.3 İndekslerin Dezavantajları
- Ek depolama alanı gerektirir.
- Veri ekleme ve güncelleme işlemlerini yavaşlatabilir.
4.9.4 İndeks Türleri:
- B-Tree İndeksleri:
- Genel amaçlı indeksler
- Hash İndeksleri:
- Eşitlik karşılaştırmaları için hızlı
- Bitmap İndeksleri:
- Düşük kardinaliteli alanlar için
4.10 Kısıtlamalar ve Veri Bütünlüğü
Kısıtlamalar, veritabanındaki verilerin doğruluğunu ve tutarlılığını sağlamak için kullanılır.
4.10.1 Birincil Anahtar (PRIMARY KEY)
Tablodaki her kaydı benzersiz olarak tanımlar.
ALTER TABLE uyeler ADD CONSTRAINT pk_uye_id PRIMARY KEY (uye_id);4.10.2 Yabancı Anahtar (FOREIGN KEY) Tablolar arasındaki ilişkileri tanımlar ve referans bütünlüğünü sağlar.
ALTER TABLE Kitap ADD CONSTRAINT fk_kitap_yayinevi_id FOREIGN KEY (yayinevi_id) REFERENCES Yayınevi(yayinevi_id);4.10.3 Benzersizlik Kısıtlaması (UNIQUE) Bir alanın benzersiz olmasını sağlar.
ALTER TABLE uyeler ADD CONSTRAINT uc_email UNIQUE (email);4.11 Kullanıcı Tanımlı Fonksiyonlar
Kullanıcı tanımlı fonksiyonlar, özel hesaplamalar yapmak için oluşturulan fonksiyonlardır.
4.11.1 Fonksiyon Oluşturma
CREATE FUNCTION toplam_odunc_sayisi(p_uye_id INT) RETURNS INT DETERMINISTIC BEGIN DECLARE odunc_sayisi INT; SELECT COUNT(*) INTO odunc_sayisi FROM odunc WHERE uye_id = p_uye_id; RETURN odunc_sayisi; END;4.11.2 Fonksiyon Kullanma
SELECT isim, soyisim, toplam_odunc_sayisi(uye_id) AS odunc_sayisi FROM uyeler;
- Düşük kardinaliteli alanlar için