data101
5. Makine Öğrenmesi Algoritmaları
5.1. Denetimli Öğrenme
5.1.1. Lineer Regresyon
Amaç:
Bağımsız değişkenler ile bağımlı değişken arasındaki doğrusal ilişkiyi modellemek.
Model Formülü:
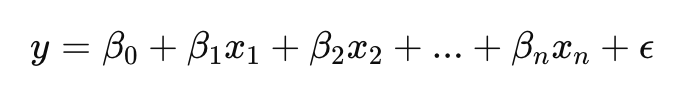
from sklearn.linear_model import LinearRegression
# Özellik ve hedef değişkenlerin belirlenmesi
X = df[['yas', 'tecrübe']]
y = df['gelir']
# Model oluşturma ve eğitme
model = LinearRegression()
model.fit(X, y)
# Tahmin yapma
y_pred = model.predict(X)
5.1.2. Lojistik Regresyon
Amaç:
İkili sınıflandırma problemlerinde kullanılır (örneğin, hastalık var/yok).
Model Formülü:
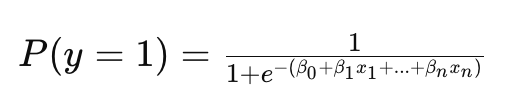
from sklearn.linear_model import LogisticRegression
# Özellik ve hedef değişkenlerin belirlenmesi
X = df[['yas', 'kilo']]
y = df['hastalik_var']
# Model oluşturma ve eğitme
model = LogisticRegression()
model.fit(X, y)
# Tahmin yapma
y_pred = model.predict(X)
5.1.3. Karar Ağaçları ve Rastgele Ormanlar
Karar Ağaçları:
Verileri bölerek karar kuralları oluşturur.
Rastgele Ormanlar:
Birden fazla karar ağacının birleştirilmesiyle oluşan bir ansambl yöntemidir.
Python Örneği:
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# Karar Ağacı
dt_model = DecisionTreeClassifier()
dt_model.fit(X, y)
# Rastgele Orman
rf_model = RandomForestClassifier(n_estimators=100)
rf_model.fit(X, y)
5.2. Denetimsiz Öğrenme
5.2.1. K-Means Kümeleme
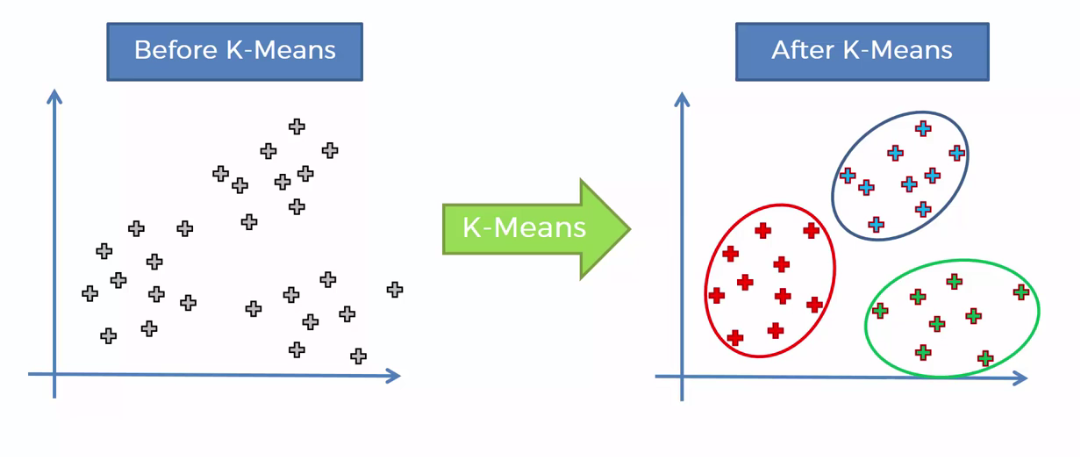
Amaç:
Verileri benzer özelliklere sahip kümelere ayırmak.
Adımlar:
- Küme merkezlerinin (k) başlangıç değerlerini belirleme.
- Her veri noktasını en yakın merkeze atama.
- Merkezleri güncelleme.
- Adım 2 ve 3’ü belirli bir kriter sağlanana kadar tekrarlama. ``` from sklearn.cluster import KMeans
Özelliklerin seçimi
X = df[[‘yas’, ‘gelir’]]
Model oluşturma ve eğitme
kmeans = KMeans(n_clusters=3) kmeans.fit(X)
Küme atamaları
df[‘kume’] = kmeans.labels_
#### **5.2.2. Ana Bileşen Analizi (PCA)**
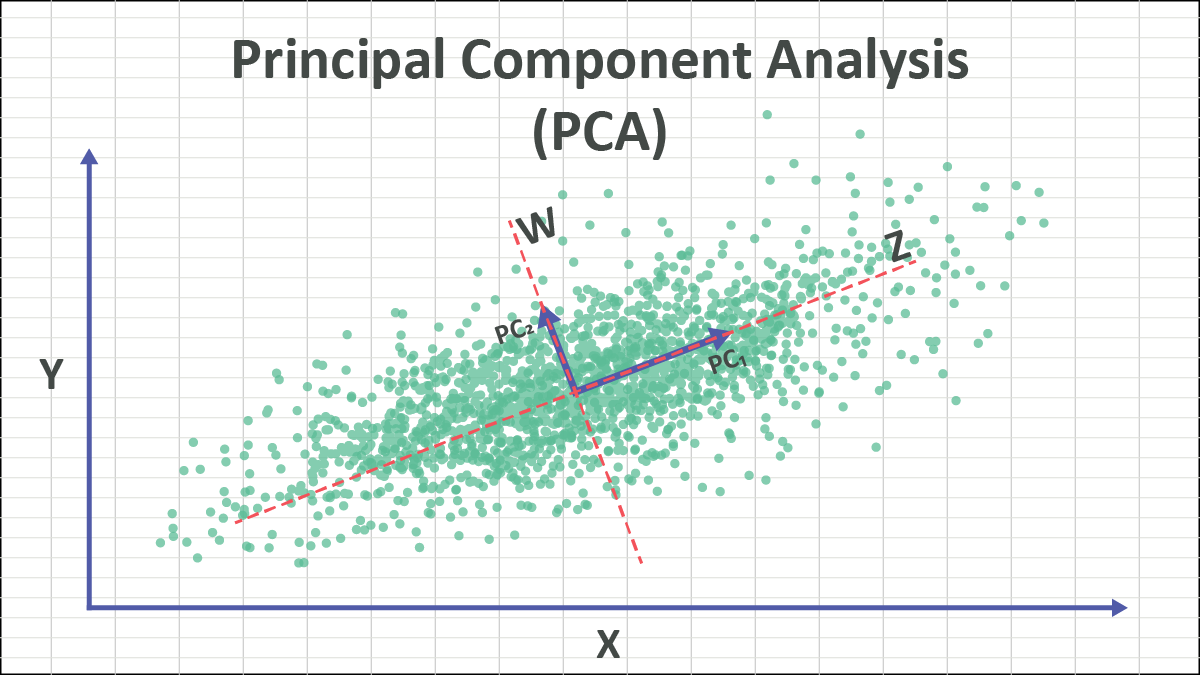
**Amaç:**
Yüksek boyutlu verileri daha düşük boyutlara indirgemek.
**Python Örneği:**
from sklearn.decomposition import PCA
Özelliklerin seçimi
X = df.drop(‘hedef’, axis=1)
PCA uygulama
pca = PCA(n_components=2) X_pca = pca.fit_transform(X)
## **6. Model Değerlendirme ve Doğrulama**
### **6.1. Model Performans Metrikleri**
**Sınıflandırma Problemleri İçin:**
- **Doğruluk (Accuracy):** Doğru tahminlerin toplam tahminlere oranı.
- **Kesinlik (Precision):** Doğru pozitiflerin toplam pozitif tahminlere oranı.
- **Hatırlama (Recall):** Doğru pozitiflerin gerçek pozitiflere oranı.
- **F1 Skoru:** Kesinlik ve hatırlamanın harmonik ortalaması.

**Python Örnek Kodu:**
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
Sınıflandırma için
accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred) recall = recall_score(y_test, y_pred) f1 = f1_score(y_test, y_pred)
Regresyon için
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
mse = mean_squared_error(y_test, y_pred) mae = mean_absolute_error(y_test, y_pred) r2 = r2_score(y_test, y_pred)
### **6.2. Çapraz Doğrulama ve Hiperparametre Optimizasyonu**
**Çapraz Doğrulama (Cross-Validation):**
Veri setini eğitim ve test setlerine bölerken, modelin genelleme kabiliyetini artırmak için kullanılır.
**K-Fold Çapraz Doğrulama:**

Veri seti k adet alt sete bölünür. Model k kez eğitilir ve her seferinde farklı bir alt set test için kullanılır.
**Hiperparametre Optimizasyonu:**
Modelin performansını artırmak için en iyi hiperparametreleri bulma işlemidir.
## **7. Uygulama: Python ile Makine Öğrenmesi Projesi**
### **7.1. Proje Tanıtımı**
**Amaç:**
Bir bankanın müşterilerinin kredi başvurularını onaylayıp onaylamama kararını tahmin eden bir makine öğrenmesi modeli oluşturmak.
**Veri Seti:**
- **Değişkenler:**
- **Yaş**
- **Gelir**
- **Kredi Skoru**
- **Borç Miktarı**
- **Kredi Onayı (Evet/Hayır)**
### **7.2. Adım Adım Uygulama**
#### Adım 1: Kütüphanelerin İçe Aktarılması
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
#### Adım 2: Veri Setinin Yüklenmesi
df = pd.read_csv(‘kredi_veri.csv’)
#### Adım 3: Veri Ön İşleme
**'kredi_onayi' sütununu sayısal değerlere dönüştürme**
le = LabelEncoder()
df[‘kredi_onayi’] = le.fit_transform(df[‘kredi_onayi’])
**Eksik verilerin kontrolü:**
df.isnull().sum()
**Eksik verilerin doldurulması:**
df[‘yas’].fillna(df[‘yas’].mean(), inplace=True)
df[‘gelir’].fillna(df[‘gelir’].mean(), inplace=True)
**Eksik olan kritik verileri datasetten çıkartalım**
df.dropna(subset=[‘kredi_skoru’], inplace=True)
#### Adım 4: Keşifsel Veri Analizi
**Tanımlayıcı istatistikler:**
df.describe()
**Korelasyon analizi:**
sns.heatmap(df.corr(), annot=True) plt.show()
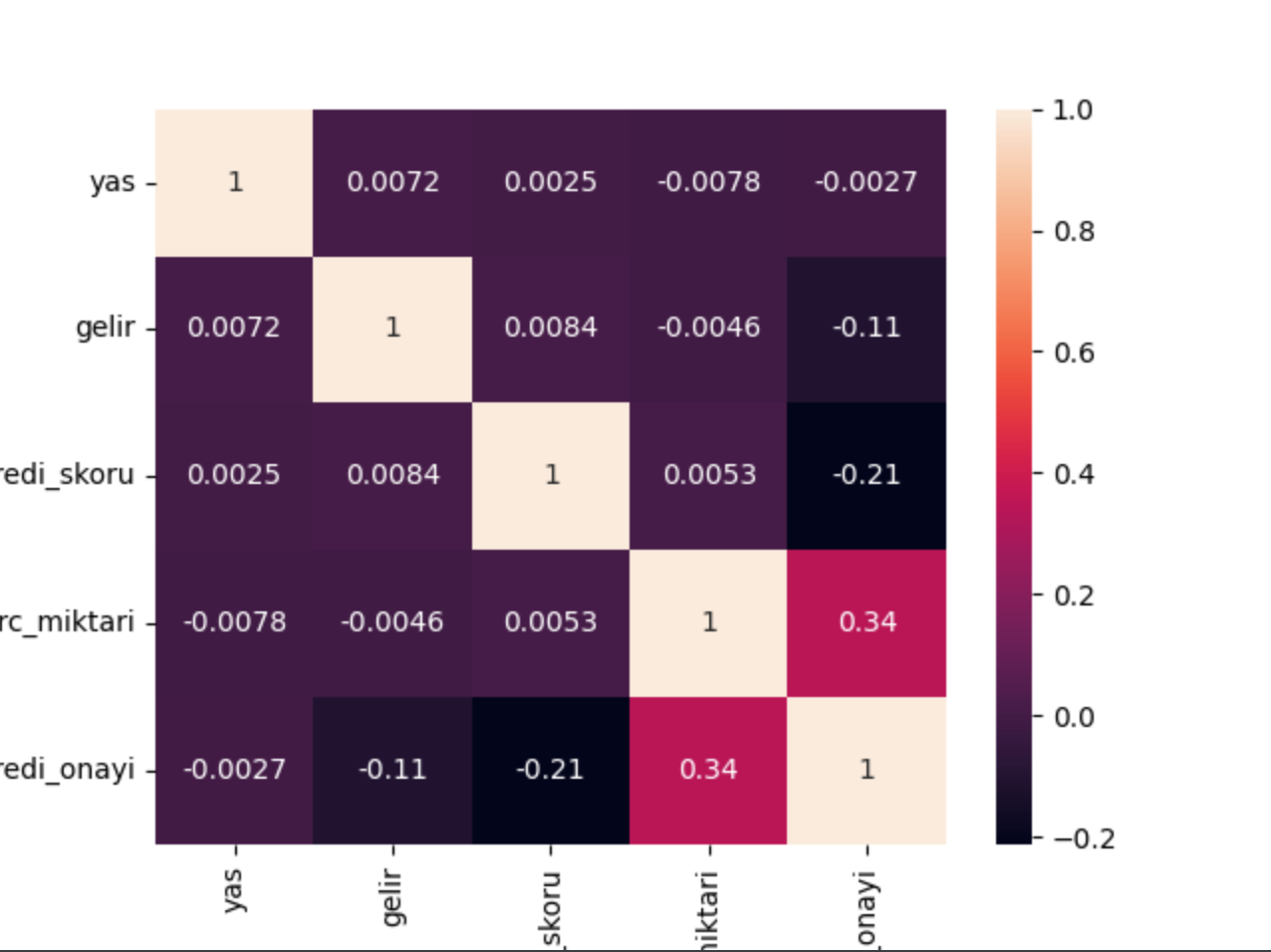
#### Adım 5: Modelleme
**Özellik ve hedef değişkenlerin belirlenmesi:**
Bağımsız değişkenler ve hedef değişken olarak ayırma
X = df.drop(‘kredi_onayi’, axis=1)
y = df[‘kredi_onayi’]
**Verinin eğitim ve test setlerine bölünmesi:**
from sklearn.model_selection import train_test_split
Eğitim ve test setlerine ayırma
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
**Model oluşturma ve eğitme:**
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
Modeli eğitme
model.fit(X_train, y_train)
#### Adım 6: Model Değerlendirme**
**Tahmin yapma:**
y_pred = model.predict(X_test)
**Performans metrikleri:**
Performans metrikleri
print(“Doğruluk Oranı:”, accuracy_score(y_test, y_pred))
print(“\nSınıflandırma Raporu:\n”, classification_report(y_test, y_pred))
Karışıklık Matrisi
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt=’d’)
plt.xlabel(‘Tahmin Edilen’)
plt.ylabel(‘Gerçek’)
plt.title(‘Karışıklık Matrisi’)
plt.show()
#### Çıktı:
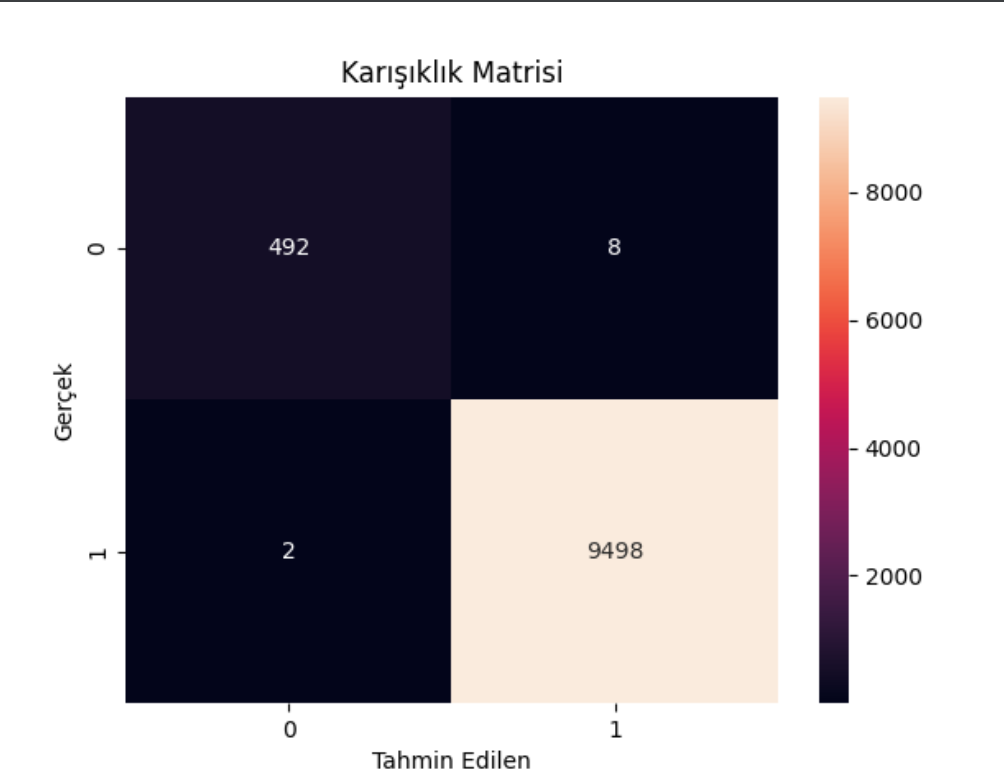
- 492 örnek doğru tahmin edilmiş (kredi onayı almayanlar).
- 9498 örnek doğru tahmin edilmiş (kredi onayı alanlar).
- 8 örnek yanlış tahmin edilmiş (kredi onayı almayanlar).
- 2 örnek yanlış tahmin edilmiş (kredi onayı alanlar).
**Doğruluk Oranı:** %99.9
#### Adım 7: Modeli Test Edelim
musteri = {
‘yas’: 32,
‘gelir’: 12000,
‘kredi_skoru’: 700,
‘borc_miktari’: 5000
}
musteri = pd.DataFrame(musteri, index=[0])
tahmin = model.predict(musteri)
print(“Tahmin:”, le.inverse_transform(tahmin](0])
#### Adım 8: Model İyileştirme **Hiperparametre optimizasyonu:
**Hafif Uyarı**: Sonuç %99.9 çıkmasının nedeni veri seti oldukça basit, Gerçek bir veri setiyle çalıştığınızda sonuçlar farklı olacaktır ve alttaki adımlar gibi modeli iyileştirmeye gitmemiz gerekecektir.
from sklearn.model_selection import GridSearchCV
Parametreler
params = {
‘n_estimators’: [100, 200, 300],
‘max_depth’: [10, 20, 30, 40, 50],
‘min_samples_split’: [2, 5, 10],
‘min_samples_leaf’: [1, 2, 4]
}
Model
model = RandomForestClassifier(random_state=42)
GridSearchCV
grid = GridSearchCV(model, params, cv=3, n_jobs=-1, verbose=2)
Modeli eğitme
grid.fit(X_train, y_train)
**En iyi model ile yeniden tahmin yapma:**
En iyi parametreler
print(“En iyi parametreler:”, grid.best_params_)
En iyi skor
print(“En iyi skor:”, grid.best_score_)
En iyi model
best_model = grid.best_estimator_
Tahmin yapma
y_pred = best_model.predict(X_test)
Performans metrikleri
print(“Doğruluk Oranı:”, accuracy_score(y_test, y_pred))
Karışıklık Matrisi
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt=’d’)
plt.xlabel(‘Tahmin Edilen’)
plt.ylabel(‘Gerçek’)
plt.title(‘Karışıklık Matrisi’)
plt.show()
Sonuçlar
```